MySQL索引简述
此处填写本题目的摘要
# 索引分类
# 哈希索引
局限性:
- 不支持排序和范围查询
- 不能进行多字段查询。
- 需要解决哈希冲突,不稳定
# 二叉树(红黑、AVL)
局限性:
- 层数太高,IO次数太多:树索引中每个节点的读取或者访问,都对应一次硬盘 IO 操作,二叉树的层高太高,需要多次磁盘IO效率太低。
# B树
局限性:
- 节点太大,IO次数太多:虽然层数相比二叉树要低,但是B树数据储存在节点中,这还是会导致一次IO读取的节点较少(当然比二叉树多多了)。
- 不好支持范围查询
- 查询效率不稳定,因为不同数据一次查询所经历的层数不一样
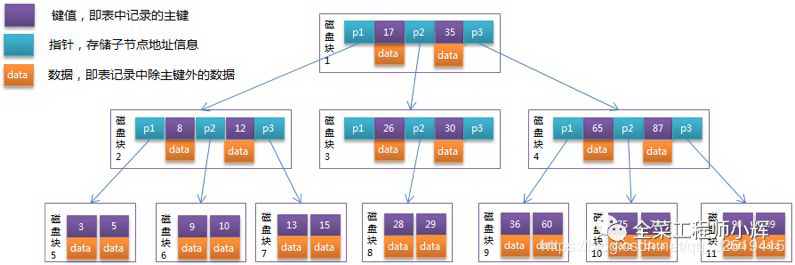
# B+树
相对 B 树,B+树做索引的优势:
- B+树的磁盘读写代价更低。B+树的内部没有指向关键字具体信息的指针,所以其内部节点相对 B 树更小,如果把所有关键字存放在同一块盘中,那么盘中所能容纳的关键字数量也越多,一次性读入内存的需要查找的关键字也就越多,相应的,IO 读写次数就降低了。
- 树的查询效率更加稳定。B+树所有数据都存在于叶子节点,所有关键字查询的路径长度相同,每次数据的查询效率相当。而 B 树可能在非叶子节点就停止查找了,所以查询效率不够稳定。
- B+树只需要去遍历叶子节点就可以实现整棵树的遍历。
# MongoDB与MySQL对比
# 为什么MongoDB索引选择B树
- 因为MongoDB不是关系型数据库,而是KV型数据库,所以对于范围查询的需求没有那么强烈。反而查询某一主键的数据会更加符合B树节点存储数据的特性。
- MongoDB的内存映射机制,数据在更新后通过修改内存然后异步刷新会磁盘中,因此效率较高,所以不涉及到MySQL修改数据需要多次IO的消耗,B树的层高问题就不是主要瓶颈。
# MongoDB为什么比MySQL效率高
首先,这个问题有陷阱,因为MongoDB的效率不总是高于MySQL的。一句话概况:牺牲了可靠性换取了效率。
- 因为MongoDB的内存映射机制,修改内存没有落盘就算操作成功,之后的刷回磁盘考OS来保证。
- MongoDB不需要提供事务的ACID特性。
- 使用MongoDB进行复杂的聚合操作,速度比较慢,这方面效率就没有MySQL高。
# MySQL索引特性
# 聚簇索引 & 非聚簇索引
- 聚簇索引:(InnoDB) 索引页+数据页组成的B+树
- 非聚簇索引:
- MyISAM:叶子节点包含的指向数据页数据行的逻辑指针
- InnoDB中:在聚簇索引之上创建的索引称之为辅助索引,叶子节点包含索引字段值和聚簇索引键

# 回表查询 、 索引覆盖
回表查询:根据非主键索引查询到的结果并没有查找的字段值,此时就需要再次根据主键从聚簇索引的根节点开始查找,这样再次查找到的记录才是完成的。
索引覆盖:只需要在一棵索引树上就能获取SQL所需的所有列数据,无需回表,速度更快。
# 索引失效条件 (opens new window)
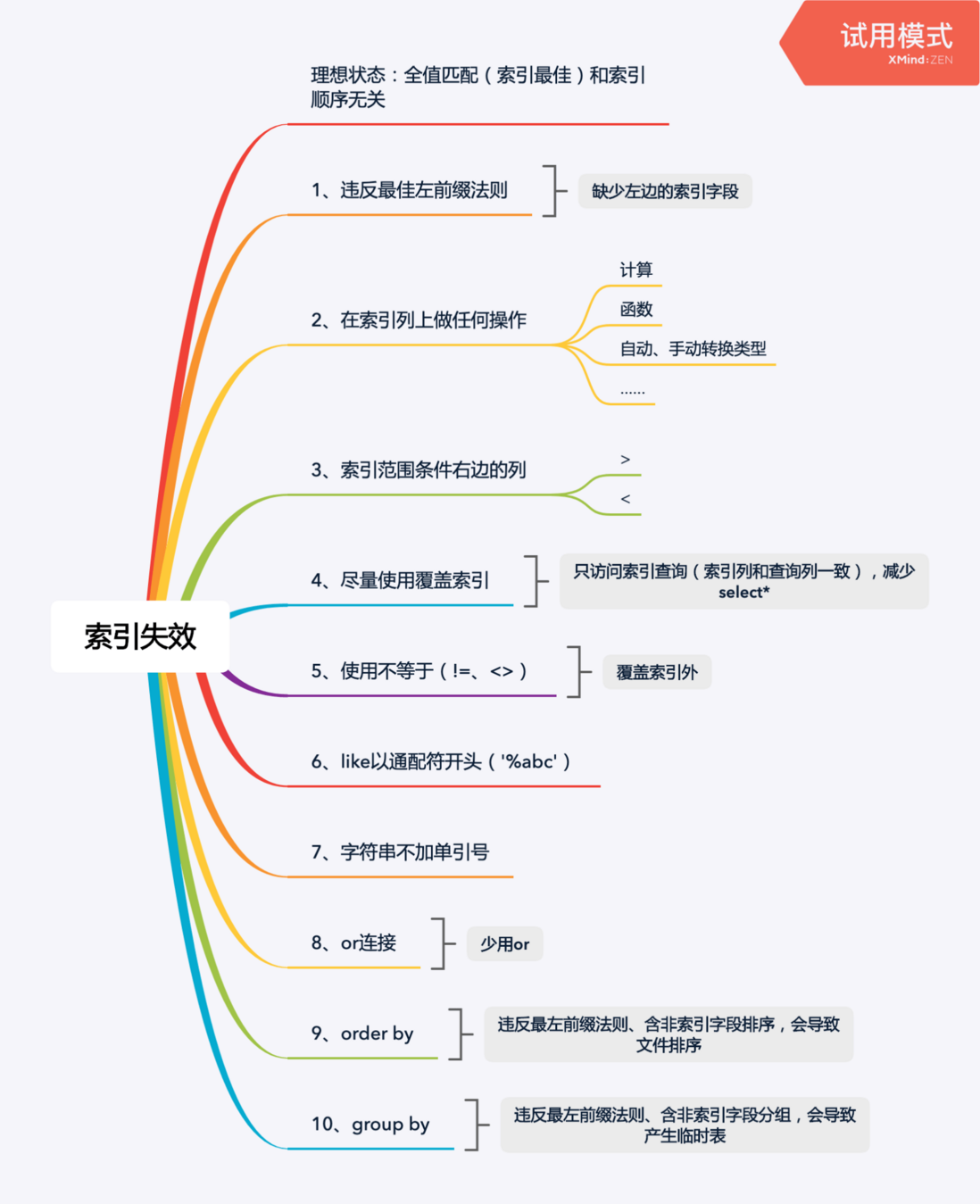
# 最左前缀原则
以最左边的为起点任何连续的索引都能匹配上。同时遇到范围查询(>、<、between、like)就会停止匹配。
即当你创建了一个联合索引,该索引的任何最左前缀都可以用于查询。比如当你有一个联合索引 (col1, col2, col3),该索引的所有前缀为 (col1)、(col1, col2)、(col1, col2, col3),包含这些列的所有查询都会使用该索引进行查询。注意:=和in可以乱序,比如a = 1 and b = 2 and c = 3 建立(a,b,c)索引可以任意顺序,mysql的查询优化器会帮你优化成索引可以识别的形式。
# 索引条件下推(ICP, index condition pushdown)
在MySQL 5.6之前,如果使用辅助联合索引,根据最左前缀匹配原则,下列SQL语句不会使用is_del键来过滤数据,这回造成多次不必要的回表。在5.6之后支持了ICP技术,即使是使用 like '%'也会对采用后续的联合索引键进行数据过滤。
mysql> select * from t_user where name like '张%' and is_del=1


# 前缀索引
因为可能我们索引的字段非常长,这既占内存空间,也不利于维护。所以我们就想,如果只把很长字段的前面的公共部分作为一个索引,就会产生超级加倍的效果。但是,我们需要注意, ORDER BY 和 GROUP BY不支持前缀索引 。
这里我们可以通过计算选择性来确定前缀索引的选择性,计算方法如下
全列选择性:
SELECT COUNT(DISTINCT column_name) / COUNT(*) FROM table_name;
某一长度前缀的选择性:
SELECT COUNT(DISTINCT LEFT(column_name, prefix_length)) / COUNT(*) FROM table_name;
当前缀的选择性越接近全列选择性的时候,索引效果越好。
# 为什么推荐使用自增长主键作为索引
结合B+Tree的特点,自增主键是连续的,在插入过程中尽量减少页分裂,即使要进行页分裂,也只会分裂很少一部分。并且能减少数据的移动,每次插入都是插入到最后。总之就是减少分裂和移动的频率。