标题
此处填写本题目的摘要
# 题目描述
- C10K、C100K
- BIO\NIO\多路IO\SIO\AIO
- Select\Poll\Epoll
- Reactor、Proactor > https://www.zhihu.com/question/26943938
- 组件场景:Redis\Nginx\
- 语言场景:NodeJS\golang
- OS场景:MacOS\Unix\Windows
- 网络库场景:Netpoll\Go Net\Netty
# C10K问题
定义:C10K问题的简要描述是:「在同时连接到服务器的客户端数量超过 10000 个的环境中,即便硬件性能足够, 依然无法正常提供服务」,即「单机1万个并发连接」问题。
虽然今天已经解决了C10K问题,但是这个问题提出的角度、解决方案相关的引申是值得关注和思考的。
# 问题来源:
在20世纪互联网初期,对与每个Client会采用一个进程来进行管理,这就会导致C10K问题,主要体现在以下几点:
- PID 限制:在互联网设计的初期,Unix操作系统采用
short来表示PID,导致在一个OS中最多只有32767个进程。所以C10K在1999年被提出时就把高并发连接限制在这个量级。当然,这在现在的Linux操作系统中得到了解决,可以让PID的取值范围变得更广。 - 内存限制:总所周知,进程之间的内存是相互隔离的,如果一个进程处理一个Client的连接,10K个进程需要消耗大量的内存资源。
- 磁盘性能:不过随着虚拟内存技术的出现,计算机的内存资源量这个限制也被转移到了磁盘上。
# 解决方案:
要解决这一问题,从网络编程技术角度看,主要思路有两个:
- 尽可能多得增加进程/线程,硬件资源不够就补充;
- 用同一进程/线程来同时处理若干连接。
# IO模型
IO模型是一种思想,在不同层面上都有具体的特指实例
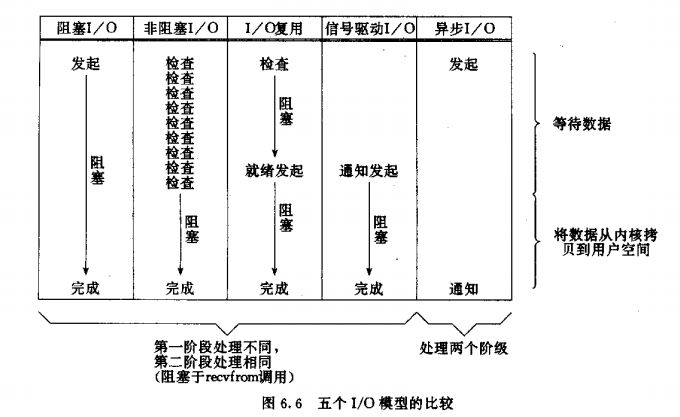
# Unix五种IO模型
这里介绍OS层的实例,特指Unix系统中的五种IO模型,可以分成两个步骤:
- 等待数据(目标数据到内核空间)
- 数据从内核空间拷贝到用户空间
- 「同步IO」:整个IO模型中用户程序会出现阻塞状态。
- 「阻塞IO」:IO模型中的第一个步骤用户程序处于阻塞状态。
- 「非阻塞IO」:IO模型中的第一个步骤用户程序处于非阻塞状态。
- 「IO复用」:一个线程可以同时处理多个FD。
- 「信号驱动IO」:同样可以同时处理多个FD,区别在于第一步骤是否阻塞。信号驱动IO不常使用的原因个人认为是不满足「单一职责」原则,处理FD的在等待数据期间可以执行其他操作,虽然增加了CPU的利用率,但也会让这个系统的设计变得更加复杂。
- 「异步IO」AIO:IO模型中的两个步骤全由内核处理,用户程序不会阻塞。
# Select\Poll\Epoll
如上文所述,I/O多路复用就是通过一种机制,一个进程可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。I/O多路复用设计模式应用更广泛,我的理解是其更加符合SOLID原则。
谈到I/O多路复用就不可避免说起Linux中的select, poll, epoll系统调用。select、poll、epoll的区别如下:
| select | poll | epoll | |
|---|---|---|---|
| 底层数据结构 | 数组存储文件描述符 | 链表存储文件描述符 | 红黑树存储监控的文件描述符,双链表存储就绪的文件描述符 |
| 如何从fd数据中获取就绪的fd | 遍历fd_set | 遍历链表 | 回调 |
| 时间复杂度 | 获得就绪的文件描述符需要遍历fd数组,O(n) | 获得就绪的文件描述符需要遍历fd链表,O(n) | 当有就绪事件时,系统注册的回调函数就会被调用,将就绪的fd放入到就绪链表中。O(1) |
| FD数据拷贝 | 每次调用select,需要将fd数据从用户空间拷贝到内核空间 | 每次调用poll,需要将fd数据从用户空间拷贝到内核空间 | 使用内存映射(mmap),不需要从用户空间频繁拷贝fd数据到内核空间 |
| 最大连接数 | 有限制,一般为1024 | 无限制 | 无限制 |
# select
# 流程:
- 用户线程调用select,将fd_set从用户空间拷贝到内核空间
- 内核在内核空间对fd_set遍历一遍,检查是否有就绪的socket描述符,如果没有的话,就会进入休眠,直到有就绪的socket描述符
- 内核返回select的结果给用户线程,即就绪的文件描述符数量
- 用户拿到就绪文件描述符数量后,再次对fd_set进行遍历,找出就绪的文件描述符
- 用户线程对就绪的文件描述符进行读写操作
# 优点
- 所有平台都支持,良好的跨平台性
# 缺点
- 每次调用select,都需要将fd_set从用户空间拷贝到内核空间,当fd很多时,这个开销很大
- 最大连接数(支持的最大文件描述符数量)有限制,一般为1024
- 每次有活跃的socket描述符时,都需要遍历一次fd_set,造成大量的时间开销,时间复杂度是O(n)
- 将fd_set从用户空间拷贝到内核空间,内核空间也需要对fd_set遍历一遍
# poll
# 流程(基本与select类型)
# 与select的不同点
- select存储的数据结构是文件描述符数组,poll采用链表
- select有最大连接数限制,poll没有最大限制,因为poll采用链表存储
# epoll
# 核心点
- epoll_create创建eventpoll对象(红黑树,双链表)
- 一棵红黑树,存储监听的所有文件描述符,并且通过epoll_ctl将文件描述符添加、删除到红黑树
- 一个双链表,存储就绪的文件描述符列表,epoll_wait调用时,检测此链表中是否有数据,有的话直接返回
- 所有添加到eventpoll中的事件都与设备驱动程序建立回调关系
# 缺点
- 只能工作在linux下
# 优点
- 时间复杂度为O(1),当有事件就绪时,epoll_wait只需要检测就绪链表中有没有数据,如果有的话就直接返回
- 不需要从用户空间到内核空间频繁拷贝文件描述符集合,使用了内存映射(mmap)技术
- 当有就绪事件发生时采用回调的形式通知用户线程
# LT和ET
LT模式:只要文件描述符还有数据可读,每次epoll_wait就会返回它的事件(只要有数据就触发)
ET模式:只有数据流到来的时候才触发,不管缓冲区是否还有数据(只有数据流到来才会触发)
# Kqueue、IOCP、libeio、io_uring
上面提到在Linux中才有epoll实现,在别的OS中也有高效IO模型的实例
- Kqueue:MacOS提供,设计模式类似Linux中的epoll,本质上也是IO多路复用。
- IOCP:Windows提供,设计模式类似Unix中提出的AIO,少有的异步IO模型实例,但是由于IOCP接口实现的复杂性,接入比较麻烦。并且基于不同OS中的生态情况,IOCP并没有比epoll优秀很多。
- libeio、io_uring:是Linux在不同内核版本的AIO模型,但是或多或少都没有完美的解决Linux AIO中的某些问题,所以不如IOCP与Windows中的地位一样稳固,总之Linux的AIO还缺少一枚银弹,需要时间的沉淀。
# Java BIO\NIO\AIO
Java不同版本也提供几种语言层面的IO模型,比较著名的BIO、NIO、AIO
- BIO:设计思路类似Unix的阻塞I/O,数据的读取写入必须阻塞在一个线程内等待其完成。
- NIO:设计思路类似Unix的非阻塞IO和复用IO结合,是一种同步非阻塞的I/O模型,在Java 1.4 中引入了 NIO 框架,对应 java.nio 包,提供了 Channel , Selector,Buffer等抽象。NIO中的N可以理解为Non-blocking,不单纯是New。它支持面向缓冲的,基于通道的I/O操作方法。
- AIO:设计思路类似Unix的异步IO模型,在 Java 7 中引入了 NIO 的改进版 NIO 2,它是异步非阻塞的IO模型。异步 IO 是基于事件和回调机制实现的,也就是应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续的操作。
# 网络事件处理模式:Reactor\Proactor
网络处理模式分为Reactor和Proactor两种,同步I/O模型通常用于Reactor模式,异步I/O模型则用于实现Proactor模式。
- Reactor模式:要求主线程(I/O 处理单元) 只负责监听文件描述符上是否有事件发生,有的话就立即将该事件通知工作线程(逻辑单元)。除此之外,主线程不做任何其他实质性的工作。读写数据,接受新的连接,以及处理客户请求均在工作线程中完成。
- Proactor 模式:将所有 I/O 操作都交给主线程和内核处理,工作线程仅仅负责业务逻辑。
# Reactor
事实上,Reactor 模式也叫 Dispatcher 模式,我觉得这个名字更贴合该模式的含义,即 I/O 多路复用监听事件,收到事件后,根据事件类型分配(Dispatch)给某个进程 / 线程。
Reactor 模式主要由 Reactor 和处理资源池这两个核心部分组成,它俩负责的事情如下:
- Reactor 负责监听和分发事件,事件类型包含连接事件、读写事件;
- 处理资源池负责处理事件,如 read -> 业务逻辑 -> send;
Reactor 模式是灵活多变的,可以应对不同的业务场景,灵活在于:
- Reactor 的数量可以只有一个,也可以有多个;
- 处理资源池可以是单个进程 / 线程,也可以是多个进程 /线程;
常见的 Reactor 实现方案有三种。
- 第一种方案单 Reactor 单进程 / 线程,不用考虑进程间通信以及数据同步的问题,因此实现起来比较简单,这种方案的缺陷在于无法充分利用多核 CPU,而且处理业务逻辑的时间不能太长,否则会延迟响应,所以不适用于计算机密集型的场景,适用于业务处理快速的场景,比如 Redis 采用的是单 Reactor 单进程的方案。
- 第二种方案单 Reactor 多线程,通过多线程的方式解决了方案一的缺陷,但它离高并发还差一点距离,差在只有一个 Reactor 对象来承担所有事件的监听和响应,而且只在主线程中运行,在面对瞬间高并发的场景时,容易成为性能的瓶颈的地方。
- 第三种方案多 Reactor 多进程 / 线程,通过多个 Reactor 来解决了方案二的缺陷,主 Reactor 只负责监听事件,响应事件的工作交给了从 Reactor,Netty 和 Memcache 都采用了「多 Reactor 多线程」的方案,Nginx 则采用了类似于 「多 Reactor 多进程」的方案。