UUID生成系统
现实中很多业务都有生成唯一ID的需求,例如:
- 用户ID
- 微博ID
- 聊天消息ID
- 帖子ID
- 订单ID
https://soulmachine.gitbooks.io/system-design/content/cn/
https://zhuanlan.zhihu.com/p/82099063
在分布式系统中,经常需要对大量的数据、消息、http请求等进行唯一标识,例如:对于分布式系统,服务间相互调用需要唯一标识,调用链路分析的时候需要使用这个唯一标识。这个时候数据库自增主键已经不能满足需求,需要一个能够生成全局唯一ID的系统,这个系统需要满足以下需求:
- (必须)唯一性:全局唯一
- (推荐)高可用:不轻易宕机
- (推荐)高效性:最好支持分布式拓展
- (推荐)有序性:按照时间粗略有序(sortable by time)
# UUID
首先明确一点,在分布式这个场景下,要想高性能,只能做到粗略有序,无法保证严格有序。
常见的方式。一般来说全球唯一。UUID (opens new window)是一类算法的统称,具体有不同的实现。UUID的有点是每台机器可以独立产生ID,理论上保证不会重复,所以天然是分布式的,MongoDB的UUID就是由timestamp+machineID+ProgressID+Counter构成。
UUID uuid = UUID.randomUUID();// 23e15798-f8e6-44f3-90e5-11c43aeb5f36
优点:
1)简单,代码方便。 2)生成ID性能非常好,基本不会有性能问题。 3)全球唯一,在遇见数据迁移,系统数据合并,或者数据库变更等情况下,可以从容应对。
缺点:
1)没有排序,无法保证趋势递增。 2)UUID往往是使用字符串存储,查询的效率比较低。 3)存储空间比较大,如果是海量数据库,就需要考虑存储量的问题。 4)传输数据量大 5)不可读。
优化方案
1.UUID to Int64(解决了不可读、传输数据量大) 2.转成13位长整型(现公司商品库ID方案,这种方案我隐隐觉得在一定量级情况下,会有重复ID问题)
# 单主实例MySQL主键自增
利用MySQL的 auto_increment特性,是中小型场景最优解。
优点:
- 简单,代码方便,性能可以接受。
- 数字ID天然排序,精确有序,对分页或者需要排序的结果很有帮助。
缺点:
- 可读性,容易暴露出库信息(今天下个订单,第二天同时间下个订单,其实就可以推测出该系统一天的订单量)。
- 在性能达不到要求的情况下,比较难于扩展。
- 如果遇见多个系统需要合并或者涉及到数据迁移会相当痛苦。
- 在单个数据库或读写分离或一主多从的情况下,只有一个主库可以生成。有单点故障的风险。
# 多主实例MySQL + 流量均衡器
假设用8台MySQL服务器协同工作,第一台MySQL初始值是1,每次自增8,第二台MySQL初始值是2,每次自增8,依次类推。前面用一个 round-robin load balancer 挡着,每来一个请求,由 round-robin balancer 随机地将请求发给8台MySQL中的任意一个,然后返回一个ID。
优点:
- 使用流量均衡器可以打到分布式ID的时间相对有序。
- 多主MySQL写入,分布式效率高于单实例。
- 多台服务器协同工作,一两台宕机了还可以保证运行,可用性得到保证。
# Flickr Ticket Servers
全局通用库,实现思路(auto_increment + replace into + MyISAM),用 REPLACE INTO 代替 INSERT INTO 的好处是避免表行数太大,还要另外定期清理。 stub 字段要设为唯一索引,这个 sequence 表只有一条纪录,但也可以同时为多张表生成全局主键, 例如 user_ship_id。除非你需要表的主键是连续的,那么就另建一个 user_ship_id_sequence 表。 经过实际对比测试,使用 MyISAM 比 Innodb 有更高的性能。
1). 创建64位的自增id:
CREATE TABLE `uid_sequence` (
`id` bigint(20) unsigned NOT NULL auto_increment,
`stub` char(1) NOT NULL default '',
PRIMARY KEY (`id`),
UNIQUE KEY `stub` (`stub`)
) ENGINE=MyISAM;
SELECT * from uid_sequence:
+-------------------+------+
| id | stub |
+-------------------+------+
| 72157623227190423 | a |
2
3
4
5
6
7
8
9
10
11
2.如果我需要一个全局的唯一的64位uid,则执行:
REPLACE INTO uid_sequence (stub) VALUES ('a');SELECT LAST_INSERT_ID();
优点:
1.简单,逻辑容易理解。 2.数字ID天然排序,对分页或者需要排序的结果很有帮助。 3.即使为多个服务生成ID,数据也只有一条。 4.即使遇见多个系统(通过同样ID生成器生成)合并,也不会出现冲突。 5.双库生成,没有单点故障的风险。
缺点:
1.可读性,容易暴露出库信息。(当然如果你为多个服务生成ID,则没有该问题) 2.数据库性能瓶颈
# Redis生成方案
原理:可以用Redis的原子操作 INCR和INCRBY来实现
优点:
1)不依赖于数据库,灵活方便,且性能优于数据库。 2)数字ID天然排序,对分页或者需要排序的结果很有帮助。
缺点:
1)如果系统中没有Redis,还需要引入新的组件,增加系统复杂度。 2)需要编码和配置的工作量比较大。
# Snowflake
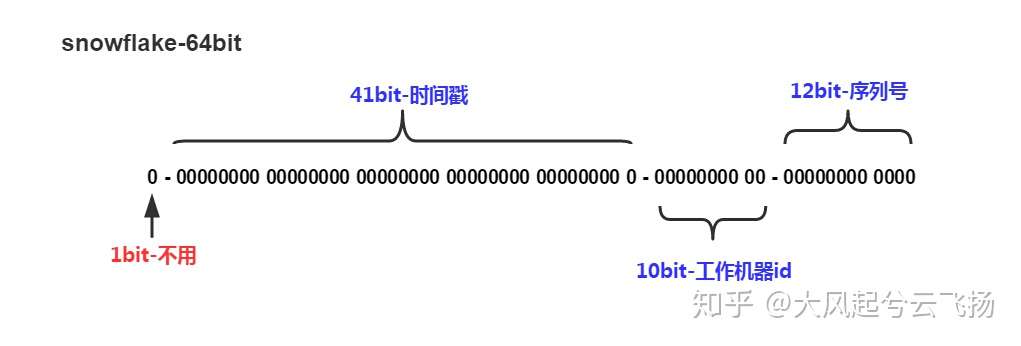
信息说明:
1位:暂没有使用,二进制中最高位为1的都是负数,但是我们生成的id一般都使用整数,所以这个最高位固定是0
41位:时间戳数据区,用来记录时间戳(毫秒) 41位可以表示241−1个数字, 如果只用来表示正整数(计算机中正数包含0),可以表示的数值范围是:0 至 241−1,减1是因为可表示的数值范围是从0开始算的,而不是1。 也就是说41位可以表示241−1个毫秒的值,转化成单位年则是(241−1)/(1000∗60∗60∗24∗365)=69年
10位:机器数据区,用来记录工作机器id 可以部署在210=1024个节点,包括 5位datacenterId 和 5位workerId 5位(bit) 可以表示的最大正整数是25−1=31,即可以用0、1、2、3、….31这32个数字,来表示不同的datecenterId或workerId
12位:序列号数据区,用来记录同毫秒内产生的不同id 12位(bit) 可以表示的最大正整数是212−1=4096,即可以用0、1、2、3、….4095这4096个数字,来表示同一机器同一时间截(毫秒)内产生的4096个ID序号
优点:
\1) 所有生成的ID都是按时间趋势递增 2) 整个分布式系统内不会产生重复ID 3) 每个ID中都可以解读出,该ID是在哪个数据中心的哪台工作机器上产生 4) 数值型的分布式ID(替换了UUID) 5) 高性能的ID生成器(超高400w/s的超高性能)(实测:限于代码以及机器性能,实际每秒生成ID在20万。
缺点:
1).在分布式部署的情况下,如果各个机器的时间出现偏离,那么就会出现顺序问题。 2).时间出现回拨,ID生成可能会出现重复。(在代码中的实现会缓存上一次ID生成的时间戳进行比对,避免了重复ID的风险,当然也让ID生成器上抛异常)